Blog 2
Next-Gen OpenSearch Serverless: Vector Search Scale-to-Zero for AI Agent Applications
What Is OpenSearch Serverless NextGen?
NextGen is the new architecture of Amazon OpenSearch Serverless, a fully managed search and vector engine. The core innovation is that it completely decouples compute and storage through a shared storage layer, allowing compute capacity to scale independently of data volume. This enables the service to provision resources in seconds and scale all the way to zero when idle.
AWS names the two architectures: older collections are now called Classic, while the new architecture is NextGen and is the default when creating new collections via the Console. In API/CLI, you specify --generation NEXTGEN (or --generation CLASSIC to keep the old architecture).
Problems with the Classic Architecture
The original Serverless architecture always maintained a minimum of two OpenSearch Compute Units (OCUs) running at all times. This makes sense for a production search engine with steady traffic, but is wasteful for agent-type workloads:
- Paying while idle: Compute is always allocated at a minimum level, so you’re charged even with no queries.
- Compute tied to storage: You cannot scale compute independently without affecting stored data.
- Slow scaling: Resource provisioning takes minutes, making it hard to keep up with sudden traffic spikes in agentic workflows.
How NextGen Works: Separating Compute & Storage
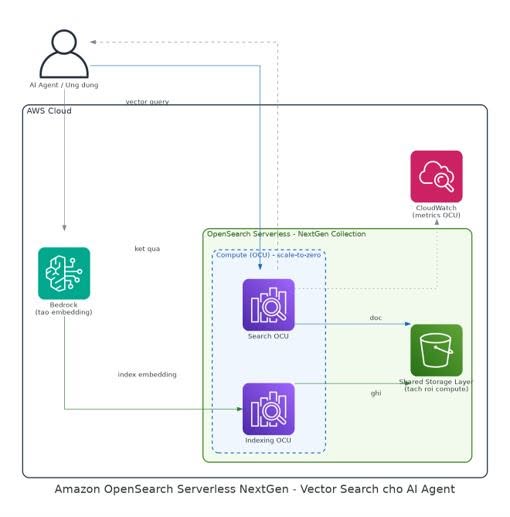
NextGen’s fundamental change is separating compute from storage. A new shared storage layer is accessed by both indexing OCUs and search OCUs, allowing OCUs to scale up or down regardless of stored data volume. You can have multiple indexes with data without incurring compute costs when not indexing or searching.
The architecture diagram below illustrates how NextGen serves an AI agent: the agent creates embeddings via Bedrock and writes to the Indexing OCU; vector queries go through the Search OCU. Both Indexing OCU and Search OCU (compute layer) scale independently and share a separate Shared Storage Layer, enabling scale-to-zero when idle.
Key Highlights & Core Benefits
- True scale-to-zero: When no requests arrive within the idle window (10 minutes), the service releases compute and OCUs to zero — compute billing stops. When traffic returns, capacity recovers within approximately 10 seconds.
- 20x faster scaling: Resources are created in seconds and capacity scales 20x faster than the previous generation, handling even the most unpredictable agentic workflows.
- Up to 60% cost savings: For workloads with significant idle time, the new architecture reduces infrastructure costs by up to 60% compared to provisioning for peak load.
- AI-native integration: Built-in integration with AI development platforms like Vercel and Kiro; part of OpenSearch Agent Skills for direct use in Claude Code, Cursor, Codex via natural language commands.
Ideal Use Cases
- Vector backend for AI agents: Store and query vector embeddings for RAG and semantic search, paying only when the agent actually queries.
- Semantic Search: Maintain vector indexes for natural language queries instead of operating your own Vector Database.
- Unpredictable workloads: For example, an e-commerce platform seeing 10x traffic spikes during flash sales then dropping to zero — instant scaling without pre-provisioning for peak.
- Dev/test environments: Express Create quickly builds a collection with default policies, useful for experimentation (production should configure encryption, network, and data access intentionally).
Release Status
The new generation of OpenSearch Serverless was announced on May 28, 2026 and is GA. At launch, two collection types are supported: full-text search and vector search. Collections can be created via Console, AWS SDK, and AWS CLI; AWS CloudFormation support is coming soon. Note: ‘shared storage’ still incurs GB-month storage charges even when compute is at zero, so the 20x and 60% figures are conditional, tied to specific baselines and workloads with significant idle time.
Conclusion
OpenSearch Serverless NextGen directly addresses the cost challenge of the AI agent era: bursty traffic followed by silence. By decoupling compute and storage to scale to zero, it enables deploying production-ready search and vector backends in minutes, paying only for actual usage. This is a natural fit for RAG and semantic search architectures without needing to operate a separate Vector Database.